What is a Page?
A webpage or page quantifies the volume of consumption of our data services. As a result, one of the main variables in our pricing is the number of pages (or specifically webpages) that we scrape. The more you consume, the more it costs (with increasing volume discounts lowering that per page cost).
For our billing purposes we use the global definition of a page as a HTTP request (generally a HTTP GET or POST request but could be more). A redirect request can trigger more page requests and AJAX or XHR requests can trigger more page requests.
On this page, we will attempt to provide most details on what constitutes a “page” and how that is different from a HTTP GET/POST request or “fetching a URL” (URL count) or a “record count”.
What is a Page
When the Internet was first built, the answer to this was very simple – most “pages” on the web were static and typed by someone and each page had a unique URL, so if you accessed a URL, you would usually get one page.
However, if the page contained images, scripts etc. – each of those, while part of the page would be requested separately from the website using what is normally a HTTP GET request. So one page request could lead to 10 or 100 (or more) URLs being fetched from one or multiple websites while being shown as one page on your browser.
Here is an example of a (formerly) popular website yahoo.com. If someone were to scrape the one page at http://www.yahoo.com/ – it would require the following
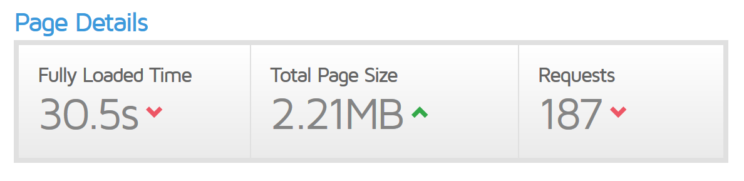
No wonder the page is slow – it requires a massive 187 GET or URL requests ! This includes all the images, ads that you see and that pay to keep Yahoo alive, scripts, videos, tracking scripts etc. So what seems like ONE page could actually be 187 pages (ie HTTP get requests).
When is one page more than one page
As the web got more complicated and dynamic, what appears to be on one page actually may get generated by multiple page requests. Let take this example of a shoe on Amazon.com at https://www.amazon.com/Nike-Revolution-White-Black-Running/dp/B010OC8FUK
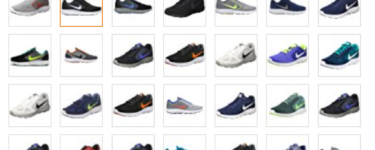
Every time you even hover over each of these thumbnails – a new URL is silently fetched from the server (using AJAX/XHR requests). Also, when you change the size a new page or pages are fetched from Amazon.
Sometimes it is obvious that you are getting a new page and sometimes it isn’t. In case of Amazon, the Price or Availability of the item may change, but in case of a site like Zillow, it may just fetch the Sale price history of a property which was hidden previously
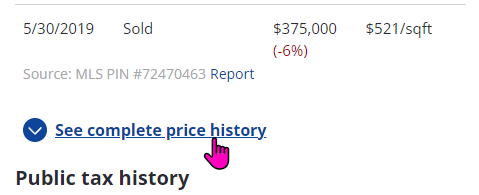
This additional page request can only be verified using the “Developer Tools” section of your web browser.
If you want the reviews for this shoe you end up at https://www.amazon.com/Nike-Mens-Revolution-Running-Shoe/product-reviews/B01N7XW7LN/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=avp_only_reviews&sortBy=recent
and then each page you traverse is at least a new page request such as https://www.amazon.com/Nike-Mens-Revolution-Running-Shoe/product-reviews/B01N7XW7LN/ref=cm_cr_arp_d_paging_btm_next_2?ie=UTF8&reviewerType=avp_only_reviews&sortBy=recent&pageNumber=2
While it may seem we are getting data for just one amazon product on one page, it can translate into many pages – even hundreds of page per product.
Visible vs Invisible Page Changes
Some page changes are visible e.g. in case where there is an explicit link to click for the next page like this

However, there are many websites where the pages automatically change to the next page in what is called “infinite scrolling”. The next page is “clicked automatically for you” as soon as you reach the end of the page.
This hidden or silent clicking also counts as a new page for our billing because it is a new page that is loaded from the website.
What is a Record count
Records are something you may need – for example you may need each product to be in one record or one property or job or business listing to be in one record. There may or may not be a relationship between the pages that we need to scrape.
e.g. if you look up Car Wash place in New York on Yellow Pages
https://www.yellowpages.com/search?search_terms=Car+Wash&geo_location_terms=New+York%2C+NY
Here are the kind of results you see:
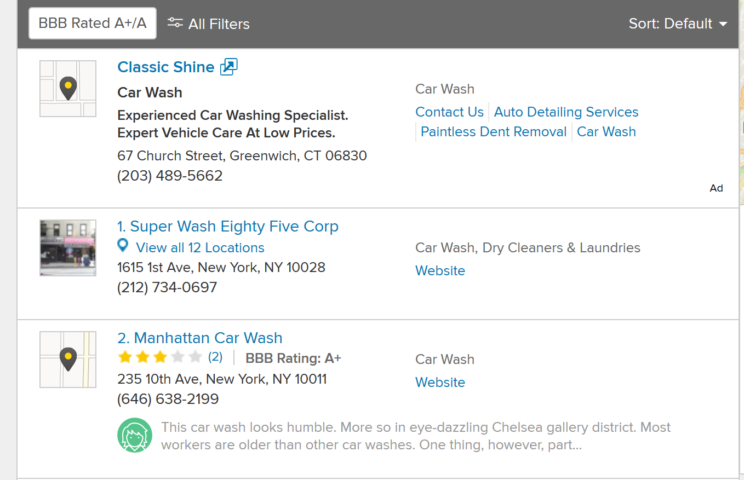
If all the data you need is right there on the page and we do not need to click on each entry to get the data, we are fetching only One page BUT we end up getting multiple records (or listings) from that One page.
In this example yp.com shows 30 results per page, so for each page you would get 30 “records”.
However, if the data that you need is on the details page of a business such as https://www.yellowpages.com/new-york-ny/mip/super-wash-eighty-five-corp-457191653?lid=457191653
In that case we not only have to get the first page but 30 other pages per page of listing.
Same in the case of Amazon reviews – while you may get a single “record” for one product/ASIN on Amazon, it may take hundreds of pages to compile that record for you.
Page count for Direct pages vs Navigation vs Search
If you provide us an ASIN, we can go directly to that page e.g. if you provide us B010OC8FUK, we can go directly to amzn.com/B010OC8FUK or https://www.amazon.com/dp/B010OC8FUK/
In this case the ASIN count = Product Count = Record Count = Page Count
However, if you ask us to get products using a Category e.g. Toys and Games at https://www.amazon.com/toys/b/ref=nav_shopall_tg?ie=UTF8&node=165793011 and ask us to Navigate the category based on some criteria, we will end up scraping a lot more pages that the records that you will get because we also end up fetching pages while we navigate.
The same holds true for Searching for something on a site – the search itself consumes page requests and then the navigation of the search results consumes more pages till we get to the actual page with the data.
e.g. searching for Woody in Toys and Games
https://www.amazon.com/s/ref=nb_sb_noss_2?url=search-alias%3Dtoys-and-games&field-keywords=woody
Page count for Location specific data
Please click here to get more detail on location specific data.
Related Articles
How many page credits do I need to scrape reviews from Yelp?
Our Yelp Reviews Crawler collects data from the review listing page (one review listing page usually contains 10 reviews). e.g. If you want to scrape 100 reviews for 1 listing, then the scraper uses 11-page credits. 1 page to go to the Yelp Business ...How many page credits do I need to scrape reviews from Amazon?
Our Amazon Reviews Crawler collects data from the product listing page (one review listing page usually contains 10 reviews). e.g. If you want to scrape 100 reviews for 1 listing, then the scraper uses 11 page credits. 1 page to go to the product ...How many page credits do I need to scrape reviews from Google?
Our Google Reviews Crawler collects data from the review listing page (one Google review page usually contains 10 reviews). e.g. If you want to scrape 100 reviews for 1 listing, then the scraper uses 11 page credits. 1 page to go to the Google ...How many page credits do I need to scrape properties from Redfin?
Here are the number of page credits required for the 2 types of inputs - 1. Direct Property URLs ( https://www.redfin.com/DC/Washington/1229-12th-St-NW-20005/unit-2/home/143713943 ) 2. Search Result URLs ( https://www.redfin.com/zipcode/20005 ) ...How many page credits do I need to scrape data about businesses from Google Maps?
Our Google maps crawler needs to go through a list of all businesses and then go into each business' detail page to get additional data about each business such as their telephone, address, open hours, website address, etc. Here is the business ...